Transformer 개념 정리 (및 의역)
Transformer를 공부하면서 자료를 한글로 정리해둔 포스팅입니다.
의역이라기엔 내용도 좀 잘라먹고 주관이 많이 들어갔네요. 하지만 이해하기는 좀더 쉬울 수도 있습니다(?).
원본 링크 - The Illustrated Transformer
Transformer의 전체 구조 (A High-Level Look)
Transformer를 전체적인 구조부터 살펴보자.
![]()
Transformer는 인코더, 디코더로 나뉘어 있고 input이 n개 stack 된 인코더를 거친 후 이것이 각 n개 stack 된 디코더에 상호작용하여 output이 나오게 된다.
인코더 블록 하나는 아래와 같이 이루어져 있다.
![]()
인코더로 들어가는 input은 우선 self-attention layer를 거친다. 이 layer에서는 한 특정 단어를 encode함에 따라 인코더가 input sentence의 다른 단어들을 보는 것을 도와준다. Query, Key, Value를 통해 더 자세히 self-attention에 대해 설명할 것이다.
self-attention layer를 지난 output은 다시 feed-forward NN으로 들어간다.
디코더 또한 feed-forward NN과 self-attention layer를 갖지만 이 사이에 Encoder-decoder layer 하나를 더 갖는다. 이 layer는 디코더가 input으로 들어오는 문장의 관련 부분에 집중할 수 있게 도와준다. 이 부분은 seq2seq model에서 attention이 수행하는 것과 비슷한 역할을 한다.
![]()
텐서의 측면에서 보는 Transformer (Bringing The Tensors Into The Picture)
전체적인 구조를 슥 훑어봤으니 이제 더 자세히, 벡터와 텐서들이 이 구조에서 어떻게 작용하는지 살펴보자.
Transformer에 집어넣기 전에 우선 각 input word를 NLP에서 항상 쓰이는 embedding으로 vector로 바꾼다.

보통은 벡터를 512의 길이로 (즉 512차원)으로 설정하지만, 이것은 가장 긴 문장의 길이가 될 수도 있고 우리가 따로 설정할 수 있는 Hyperparameter이다.
문장의 각 단어가 임베딩되면 첫 인코더에서 아래와 같이 진행된다.
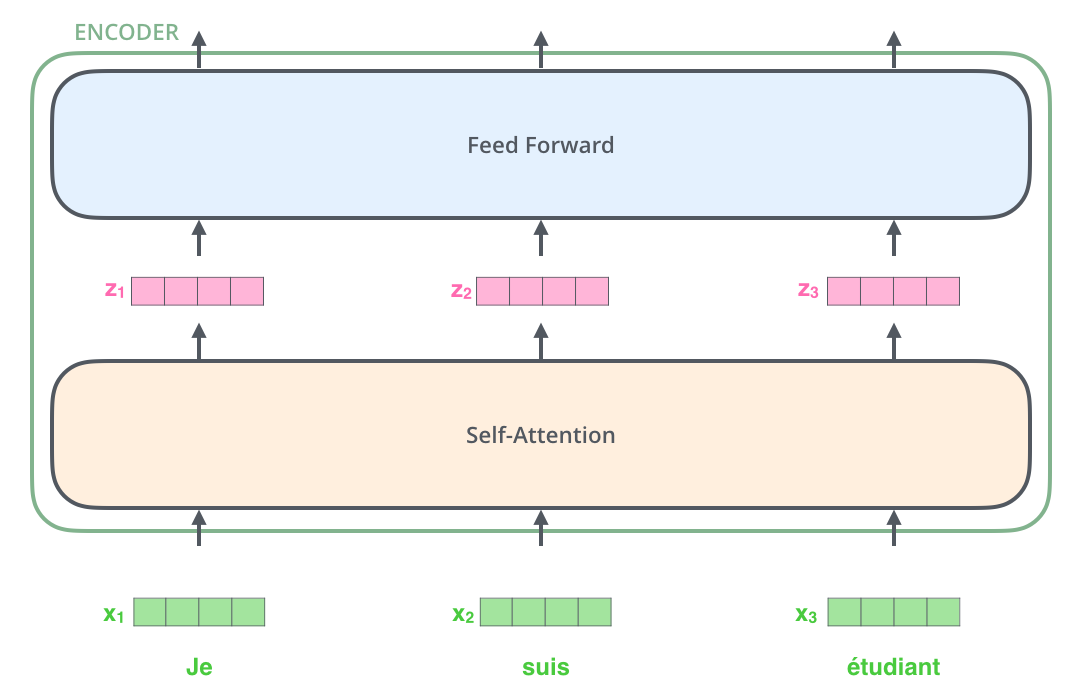
Transformer에서 중요한 속성이 있는데, 각 위치의 단어가 인코더의 자체 경로를 통해 흐른다는 것이다. self-attention layer에서 이러한 경로들은 서로 의존성을 가진다. 한 단어당 모든 단어들을 고려하므로 모두 종속되어 있는 것이다. 하지만 feed-forward layer에는 이러한 순서의 종속성이 없으므로 이 layer에서는 병렬적으로 실행이 일어난다.
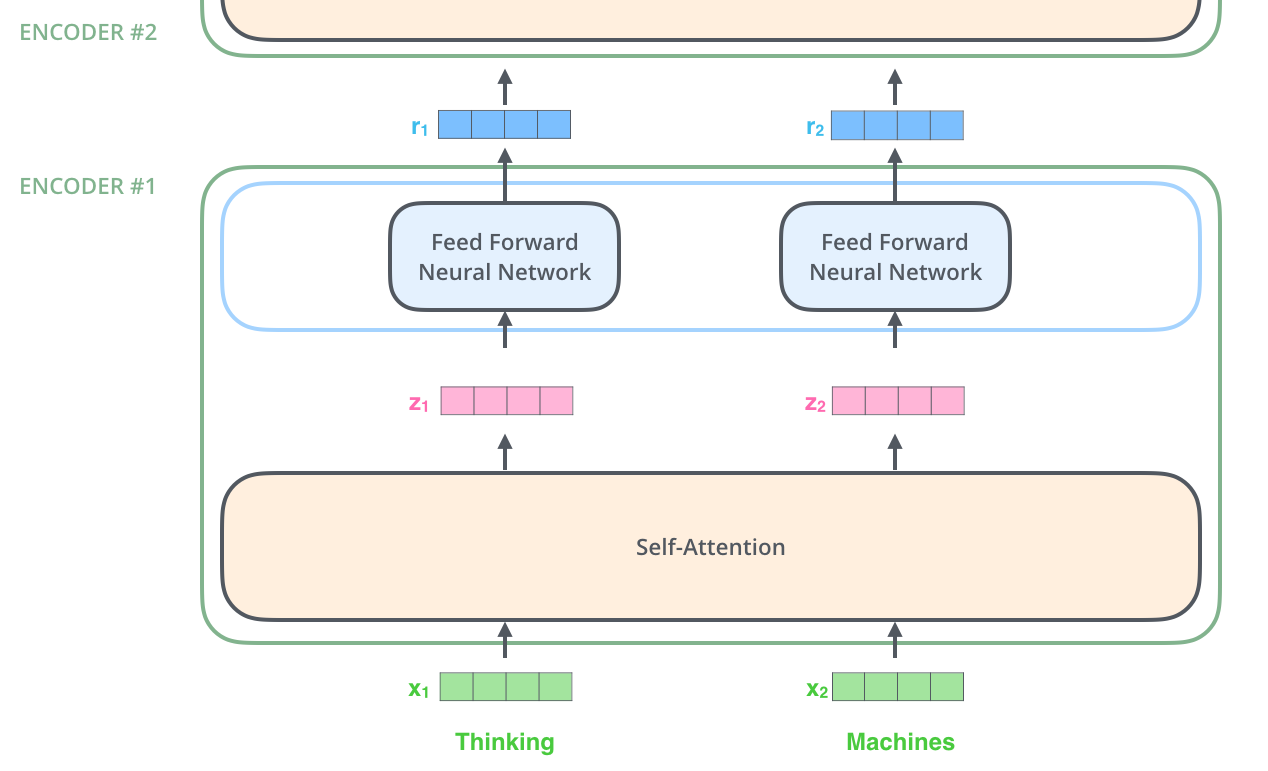
따라서 아래와 같이 두 단어가 들어갔을때, feed-forward NN에서 단어는 병렬적으로 처리될 수 있다.
Self-Attention 란 무엇인가? (Self-Attention at a High Level)
원문의 저자도 Self-Attention에 대해서 논문을 읽어보기 전까지 단어 자체의 뜻이 잘 와닿지 않았다고 했다. (ㅋㅋ)
The animal didn't cross the street because it was too tired
이 문장에서 it은 어떤 부분과 관련이 있는가? 당연히 animal이지. 하지만 알고리즘적으로는 어떻게 알려줄수 있을까?
이것에 대해 RNN은 단어 사이의 관련성을 hidden state를 이용해 이전 단어들을 기억하는 방식으로 구현했다면, Transformer에서 사용하는 self-attention은 모델이 input sequence를 훑으며 한 단어를 살펴볼때 input sequence의 다른 단어 들을 살펴보며 이 단어를 어떻게 인코딩할지 판단하게 해준다.
Self-Attention의 동작 원리 (Self-Attention in Detail)
먼저 벡터를 통해 어떻게 self-attention이 계산되고, 행렬을 통해 어떻게 실제로 적용되는지 살펴보자.
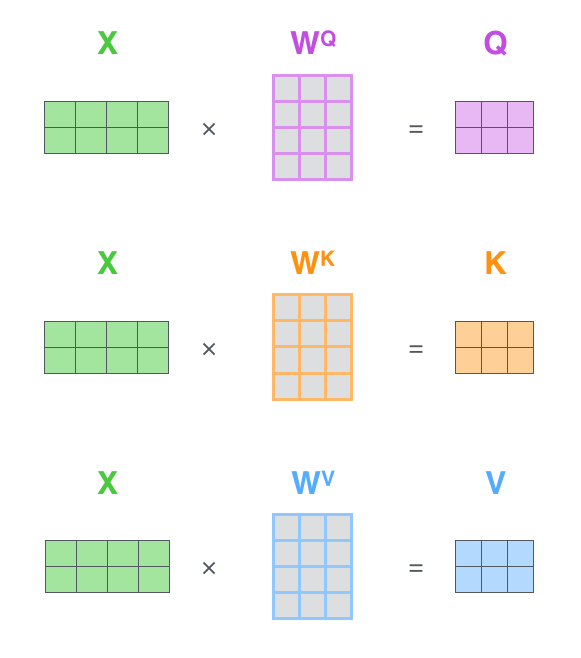
첫번째로, 각 input 벡터, 즉 각 단어의 embedding에서 세 벡터를 생성한다. 이 세 벡터를 각각 Query, Key, Value 벡터라고 한다. 이를 생성하기 위해서는 Query, Key, Value 가중치 행렬이 각각 필요하다. 예를 들어, 아래 그림의 Query 벡터는 단어 embedding과 Query 가중치 행렬 W^Q를 서로 행렬곱하여 생성한다. (1x4 벡터 X 4x3 행렬 = 1x3 벡터)
여기에서 단어 embedding 벡터로부터 새롭게 생성된 Q, K, V 벡터는 더 작은 차원을 (길이를) 가진다. 꼭 작아야 할 필요는 없지만 multi-headed attention 계산의 일관성을 위해 이렇게 이용한다고 한다.
![]()
그럼 Query, Key, Value 벡터란 각각 어떤 의미를 가질까?
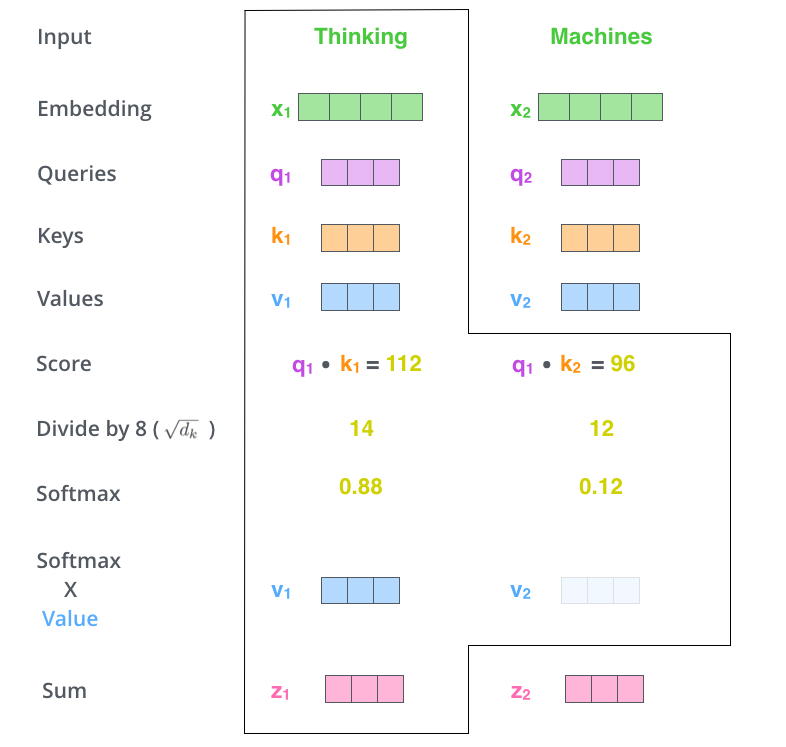
두번째로, 점수 계산이다. 각 단어에 대해서 다른 단어들에 점수를 부여하고 이 점수에 따라 해당 단어 인코딩시 다른 단어의 중요도를 체크할 수 있다.
이 ‘점수’는 인코딩할 단어의 Query 벡터에, 점수를 부여할 단어의 Key 벡터를 내적함으로써 구한다. 예를 들어 아래의 그림에서 “Thinking”에 대한 self-attention을 진행할 때, Thinking 그 자체의 점수는 q1과 k1의 내적이고 “Machines”의 점수는 q1과 k2의 내적이다.
![]()
세번째로, 스코어를 계산했으면 gradient를 안정화할 목적으로 이것을 key 벡터의 차원 (길이)의 제곱근으로 나누어 준다 (보통 그렇다는 것. 물론 이것도 바꿀 수 있다). 64의 길이를 가진 key 벡터라면 점수를 64의 제곱근인 8로 나누어 준다.
네번째로, 나눈 결과를 softmax를 통해 모든 점수 합이 1이 되도록 값을 정규화시킨다. 이렇게 나온 값은 기준 단어가 각 위치에서 얼마나 상관성이 높은지 보여준다.
다섯번째로, 여기에서 Value 벡터가 등장한다. 계산된 점수에 Value 벡터를 곱한다. 즉 단어마다 갖는 Value 벡터에 가중치를 부여하는 것이다.
여섯번째로, 이것들을 모두 합하여 (weighted sum) self-attention layer의 output 결과가 나오게 된다.
아래의 그림에 여섯가지의 과정이 표현되어 있다.
지금까지 벡터를 통해 한 단어의 self-attention 과정을 살펴 보았다. 실제 연산은 아래와 같이 행렬로 이루어진다.
앞서 설명했던 self-attention의 output이 나오기까지의 여섯가지의 과정은 다음과 같은 식으로 요약될 수 있다.
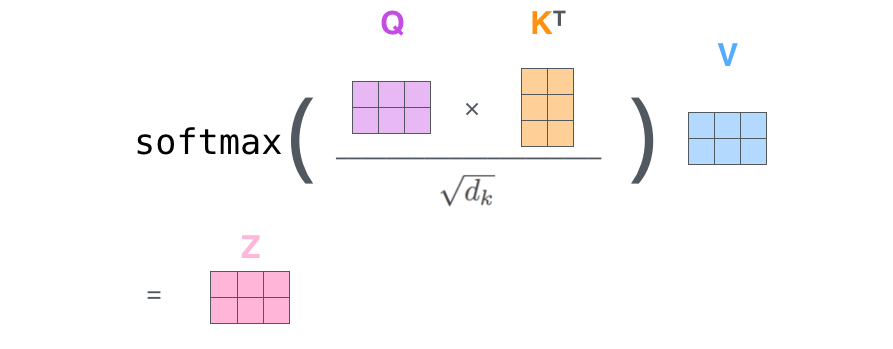
Multi-head attention 설명 (The Beast With Many Heads)
self-attention에 그치지 않고 Transformer는 multi-headed attention 메커니즘을 사용하여 두 가지 측면에서 attention layer의 성능을 향상시켰다.
- 모델이 다른 단어를 참조하는 데 도움을 준다. 예시로 위의
it이 자기자신 위치에서 가중치가 높아 다른 단어를 참조하지 못할 수도 있기 때문.- input 당 하나의 Q,K,V 만 생성하는 것이 아니라 여러 개의 Q,K,V 를 생성함으로써 ‘표현 부분공간 (representation subspaces)’을 여러 개로 만들고, 이에 따라 각 Q,K,V 세트마다 다른 특징들을 추출할 수 있게끔 한다.
![]()
Attention Is All You Need 논문에서는 8개의 multi-head를 구성하고 있다. 이것을 따라 8개의 multi-head를 구성한다면 한 input 당 아래와 같이 output이 8개 나오게 된다.
![]()
output은 1개이어야 하므로, 8개의 Zx행렬을 모두 concatenate 한 후 또다른 가중치 행렬 W^O와 행렬곱하여 1개의 최종 attention layer output을 내놓게 된다.
![]()
지금까지의 모든 과정을 다음과 같은 그림으로 요약할 수 있다.
![]()
Positional Encoding을 이용해 순서 정보 입력 (Representing The Order of The Sequence Using Positional Encoding)
지금까지의 과정에서는 input의 각 단어가 갖는 위치 정보를 고려하지 않았다. 단어가 문장에서 갖는 위치가 중요하므로 이를 부여해야 하는데, 어떻게 할 수 있을까?
Transformer에서는 위치 정보를 주기 위해 각 input embedding에 벡터를 더한다. 이 벡터는 모델이 학습할 수 있는 특정한 패턴을 따르게 되고 이를 통해 문장 내 단어의 위치 혹은 문장 내 단어끼리의 거리를 결정하는 데 도움을 준다. 이 벡터를 embedding 벡터에 더하게 되면 self-attention 과정에서 벡터끼리의 거리정보를 전달할 수 있게 된다.
![]()
예를 들어 embedding 벡터의 차원이 4라면 positional encoding은 다음 그림처럼 더해진다.
![]()
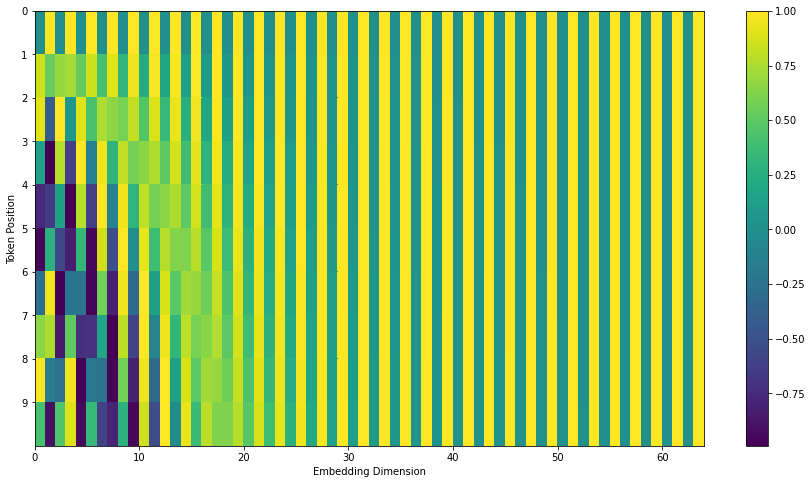
단어 embedding이 512차원인 경우의 실제 positional encoding 예시는 다음 그림과 같다. 각 행이 input sequence의 단어의 순서이고 각 단어의 embedding에 이 512차원의 행벡터가 더해진다.
![]()
위의 경우는 Transformer2Transformer에서 나오는 positional encoding이고, 실제 Attention is all you need 논문에서는 아래와 같이 sine, cosine이 서로 짜여 있는 구조 (weaving) 로 구현했다.
positional encoding의 공식은 논문의 section 3.5에 나와 있으며 이것을 생성하는 코드 예시는 get_timing_signal_1d()을 참조하자. positional encoding은 위의 방식 이외에도 다양하지만 위의 sine, cosine을 이용한 방법은 sequence length에 크게 구애받지 않는다는 장점이 있다 (train set의 sequence보다 훨씬 긴 sequence가 들어오는 경우 등)
인코더 마무리 (The Residuals)
self-attention 및 feed-forward NN은 앞서 이야기한 과정에 덧붙여 residual connection 그리고 layer-normalization을 거쳐 다음 층으로 진행된다.
![]()
벡터의 전달까지 포함하여 나타내면 다음과 같다.
![]()
이러한 과정은 디코더 내의 각 층에서도 동일하며 2개의 stacked 된 인코더와 디코더로 구성된 Transformer은 정리하여 다음과 같이 나타낼 수 있다.
![]()
디코더 (The Decoder Side)
인코더 부분에서 우리가 다뤄야할 거의 모든 개념들을 이야기했기 때문에 디코더 부분을 이해하는 것은 어렵지 않다. 그래도 디코더 부분이 어떻게 동작하는 지 한번 살펴보자.
맨 마지막 디코더 (top encoder)에서 나온 output은 self-attention에 의해 Key, Value 벡터로 변환되고 이것은 디코더에만 있는 층인 encoder-decoder attention layer에서 이용되어 인코더의 self-attention처럼 디코더가 input sequence에서 적절한 위치에 집중할 수 있게 도와준다.
![]()
디코더에서의 작업은 최종 output을 만들기까지 반복된다. 첫 단계에서의 output은 다시 다음 단계에서 디코더에게 input으로 들어가고, 이것이 디코더의 output이 종료됨을 알리는 시그널에 도달할때까지 반복하여 이루어진다. 디코더 output으로 생성된 글자는 다음 단계에서 디코더 input으로 들어갈 때 인코더에서와 같이 embedding + positional encoding이 이루어진다.
![]()
디코더가 인코더와 비교해서 갖는 중요한 차이점은 self-attention layer에 있는데, 디코더에서는 오직 output 위치의 이전 위치만 attention 할 수 있다는 것이다. 다음 위치들에 나올 단어를 모르는 상태로 attention이 이루어지며 이를 수행하기 위해 디코더에서 나온 output이 최종 softmax로 들어가기 전에 -inf로 output 위치 및 이후 위치를 모두 masking한다.
디코더의 encoder-decoder attention은 multiheaded self-attention으로 인코더에서와 동일하지만, Query 벡터만 이전 디코더에서 가져오며 Key, Value 벡터는 인코더의 output에서 가져온다는 것이 차이점이다.
The Final Linear and Softmax Layer
디코더가 output으로 내놓은 벡터를 가지고 최종적으로 linear layer과 softmax layer을 거치면서 output 단어가 나오게 된다.
먼저 linear layer는 디코더에서 나온 output vector를 가지고 모든 단어 공간으로 사상시킨다. 따라서 output vector는 linear layer를 통해 훨씬 긴 벡터로 변환되며 이를 logits vector이라 한다. 예를 들어 1만 개의 단어를 모델에게 학습시켰다면 디코더 output vector를 가지고 모든 단어에 대하여 나올 수 있는 점수 (logit)을 담아 길이 1만의 logits vector벡터 형태로 환산하게 된다.
그 다음 softmax layer에 들어가면서 이 점수들을 합이 1인 확률값으로 변환하며 가장 확률이 큰 단어가 선택되어 나오는 것으로 output 작업이 마무리된다.
마무리
원문 글에서 이 뒷부분은 일반적인 학습 및 loss 계산에 대한 부분이므로 생략합니다.
직접 정리를 하니 Transformer의 구조가 훨씬 잘 이해되는 것 같습니다. 또한 보시는 분들에게도 많은 도움이 되길 바랍니다!