CLIP: Connecting text and images
CLIP 논문 리뷰
서론
컴퓨터 비전에서의 딥러닝은 여러 문제에 직면하고 있는데, 기존의 모델을 새로운 작업에 적용시키기 매우 어렵다는 점이다. 또한 벤치마크 성능이 높은 모델이 스트레스 테스트에서 매우 성능이 저하된다는 단점도 존재한다.
이러한 문제를 해결하기 위해 여기에서 새로운 뉴럴넷을 제안했다. 인터넷에 있는 다양한 이미지와 자연어를 함께 사용하여 학습하였고, GPT-2/3 의 “zero-shot” 능력과 같이 최적화 과정을 많이 거치지 않아도 자연어를 통해 다양한 분류 과정을 지시받을 수 있다.
키 포인트는, 직접적으로 벤치마크에 최적화시키지 않음으로써 훨씬 표현력이 풍부한 모델을 얻게 된다.
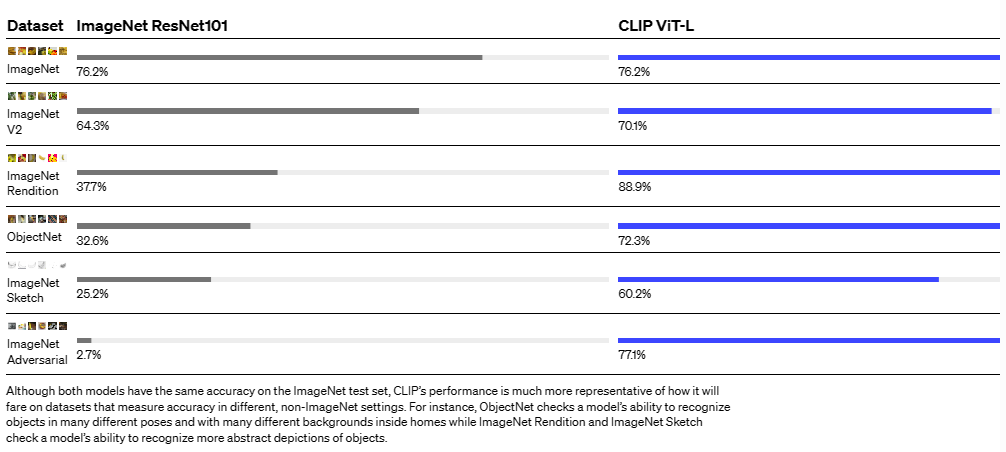
그 예시로 ImageNet의 1.28M개 이미지를 전혀 사용하지 않고 해당 이미지셋을 학습한 ResNet-50과 거의 동일한 성능을 보이면서 다른 이미지셋에 대해서는 ResNet과 비교하여 월등한 성능을 보였다.
배경
여기에서 제안하는 CLIP (Contrastive Language-Image Pre-training) 은 zero-shot transfer, natural language supervision, multimodal learning에 대한 많은 작업들을 배경으로 하고 있다.
Zero-data learning은 unseen한 물체도 분류할 수 있게 일반화하는 방향으로 연구되었고, 중요한 점은 자연어를 이용하여 일반화 및 전이가 가능하게끔 하는 것이다.
Richer Socher (2013)
CIFAR-10으로 단어 임베딩 벡터를 예측하게끔 훈련했는데 이 모델로 두 unseen class를 성공적으로 예측시켰다.DeVISE
위 방식을 이용, 확장하여 ImageNet을 fine-tune함. 이를 통해 training set의 1000가지 class object 이외의 데이터도 분류가 가능함을 보임
가장 많은 영향을 받은 연구는 FAIR (Ang Li, 2016)이다. Flickr 사진 3천만개의 제목, 묘사, 태그로 이루어진 텍스트 데이터를 이용해 훨씬 넓은 visual n-grams 문제를 예측하게끔 fine-tuning하였고, 이것으로 ImageNet zero-shot에서 11.5%의 accuracy를 획득하면서 Natural Language Supervision을 이용해 다양한 이미지셋에 대한 zero-shot transfer가 가능함을 보여주었다.
- Natural Language Supervision
- 자연어에 담겨있는 인간의 인지, 지각을 학습하는 것 ref
CLIP은 NL supervision을 이용하여 visual 표현력을 학습하는 방법론을 다시 리뷰하는 논문이기도 하다. 잘 알려진 Transformer, autoregressive 언어 모델인 VirTex, masked 언어 모델인 ICMLM, 의료 이미지에서 Contrastive Learning을 활용한 ConVIRT의 구조를 참고했다.
접근
text-image 쌍을 이용하여 image를 주면 32768개의 랜덤 샘플링된 텍스트에서 예측하는 방식으로 proxy-train시킴
이러한 훈련을 하기 위해 CLIP이 이미지의 시각적 컨셉을 넓은 범주에서 인식하고 이름과 결부시켜야 한다. 그렇게 되면 임의의 시각적 분류 작업을 수행할 수 있다.
문제 해결
Costly Datasets
비전 모델은 통상적으로 라벨된 데이터셋을 학습하는데 라벨링에 시간 및 비용이 많이 소요됨.
ImageNet dataset은 25000명이 넘는 근로자를 이용하여 1400만개의 이미지를 라벨링했지만, CLIP은 인터넷에 있는 text-image 쌍을 이용해서 학습Narrow
새로운 task에 적용하기 위해 model을 fine-tune해야 하고, 범용성이 떨어지는 문제가 있다. CLIP은 추가적인 훈련 데이터 없이도 다양한 분야의 이미지 분류가 가능하다. 새로운 작업을 CLIP이 하게 만드려면 CLIP의 text-encoder에게 작업의 개념만 알려준다. 그러면 해당 작업에 알맞는 linear classifier을 생성한다. 이 classifier은 fully supervised model과 비슷한 성능을 가진다.Poor real-world performance
cheating을 이용해 benchmark 성능은 높고 실제 성능은 낮은 경우가 있다. CLIP은 benchmark 테스트에서 거기에 해당하는 이미지를 쓰지 않기 때문에 이러한 cheating에서 자유롭고, 실제 cheating을 하는 테스트에서 성능이 더 높게 나오는 등 cheating이 좋은 성능을 내도록 만드는 경향이 있음을 확인했다.
Key takeaways
1. 효율성
알고리즘적 방법으로 훈련 효율성을 높임
- Contrastive objective for connecting text with images.
- Vision Transformer
2. 유연성 및 일반성
CLIP은 자연어로부터 시각적 개념을 폭넓게 배우기 때문에 다양한 task에 훨씬 유연하게 적용할 수 있다. CLIP의 zero-shot 성능을 fine-grained object 분류, geo-location, action recognition in videos, OCR 등 30가지 이상의 데이터셋에 적용한 결과 best ImageNet model을 상회하는 성능을 보였다.
한계
CLIP이 일반적 물체를 식별하는 데는 잘 작동하지만, 이미지에서 숫자를 세거나
(내용 추가 예정)