AudioCLIP: Extending CLIP to Image, Text and Audio
AudioCLIP 논문 리뷰
Abstract
CLIP의 확장 버전으로써 텍스트, 이미지 뿐 아니라 오디오를 다룰 수 있는 AudioCLIP을 제안하는데, 오디오 모델인 ESResNeXt를 CLIP 프레임워크에 통합시켰다. 데이터셋은 AudioSet을 이용하였다. 이를 통해 bimodal, unimodal 분류 및 querying을 가능케 하면서 CLIP의 일반성을 살려 zero-shot 추론이 가능하게끔 하였다. 이를 통해 AudioCLIP은 ESC라고도 불리는 Environmental Sound Classification에서 SOTA를 달성하였고, ESC-task에서 새로운 zero-shot을 이용한 baseline을 정확도 68%로 설정하였다.
Introduction
오디오 분야에서 그동안의 연구는 오디오 그 자체의 모달리티 (정보 전달)에만 집중했는데, 최근에는 멀티모달 형태 (여러 정보 전달)로 오디오 관련 ai task가 이루어지고 있다. 이는 주로 text 혹은 visual 정보를 함께 전달해주는 방식으로 이루어진다.
하지만 오디오에서 2개 이상의 모달리티를 결합하는 것은 많이 이루어지지 않았다. 또한 라벨링된 데이터가 많지 않아서 유니모달, 멀티모달 개발에 어려움이 있다. 이러한 데이터 부족으로 인해 zero / few-shot learning 접근에 대한 시도가 생겨났는데 이것은 text description을 이용한 contrastive learning을 기반으로 한다.
- Contrastive learning이란?
- 데이터에 있는 패턴을 학습하기 위해 유사한 (양성) 예제와 비 유사한 (음성) 예제 사이의 차이점에 초점을 맞춰, 양성 샘플과 음성 샘플 사이의 차이를 극대화하는 방식으로 동작한다. 이러한 방식으로 모델은 같은 클래스의 샘플을 가까이, 다른 클래스의 샘플을 멀리하는 방향으로 학습하여 모델이 자연스럽게 데이터를 이해하는 데 도움을 줄 수 있다.
이 연구에서는 (성능이 높다고 주장하는) 저자의 오디오 모델인 ESResNeXt를 text-image 모델인 CLIP과 결합시켜 tri-modal 구조를 구현하였다. 훈련 결과, ESC에서 기존 모델 대비 우수한 성능을 보였고 오디오 분야에서 zero-shot 능력을 갖게끔 확장시켰으며, 또한 cross-modal querying을 텍스트, 이미지, 음성 중 어떠한 조합으로도 가능하게끔 하였다.
Related Work
ESC는 알람시계, 자동차 경적, 고양이 울음소리 등 일상생활의 소리들을 적절히 라벨링하는 작업이다. 1D, 2D CNN이 raw audio의 시간-주파수 변환 작업에 이용되었는데, 1D-CNN은 해당 작업에만 특정된 구조가 적용된 반면 2D-CNN은 시각 도메인에서 가져온 형태가 도움이 됨을 보였지만 여기에선 sequential한 (순차적?) 방식으로 시각 정보가 적용되면서 한번에 한 모달리티만 적용될 수 있었다.
여러 모달리티가 같이 적용되는 사례는 영상 관련 task에서 등장하였으며 이후 소리 분류에도 적용되었다. 하지만 bi-modal까지였고 더 많은 modality를 동시에 적용하는 것이 효과적일 것이란 연구가 등장했다. 이러한 연구들에서는 공통적으로 비교 학습 (Contrastive Learning) 을 통한 self-supervised learning을 통해 적은 라벨링 데이터를 극복할 수 있을 것으로 보았고, 그러한 방식으로 비교 학습이 zero-shot 분류에 적용될 것으로 기대했다.
이와 연관지어 이 연구는 비교 학습을 텍스트, 시각, 오디오 모달리티에 적용하여 특정 모달리티에서의 분류 혹은 더 일반적으로 querying 및 zero-shot 추론에 적용할 수 있게 구성하였다.
Model
ESResNeXt + ResNet-based CLIP 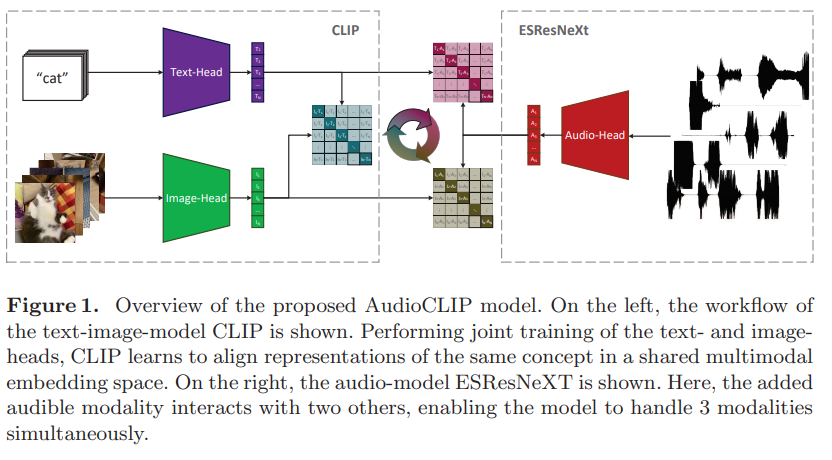
1. CLIP
CLIP은 두 가지의 encoding heads (text / image) 로 두 subnetworks로 구성된다. 둘 모두 Natural language supervision으로 pre-trained 되고, 이를 통해 라벨을 제공해주면 추가적인 fine-tuning 없이 image 인식에 대한 일반화된 성능을 보인다.
text encoding 부분에서는 약간 수정된 Transformer가 이용되고 12-layer로 구성된 모델에서 input text가 49408의 길이를 갖는 형태로 표현된다. Sequence length는 76으로 제한되었다.
image encoding 부분에서는 Vision Transformer (ViT), 수정된 ResNet-50 이 두가지를 제안하고 있으며. 본 연구에서는 이 중 계산복잡도가 더 낮은 ResNet-based CLIP 을 이용하고 있다.
두 CLIP-subnetwork에서는 input에서부터 embedding을 생성하고 이후 1024의 크기를 갖는 multimodal embedding 공간으로 선형 변환된다. 이 셋업에서 CLIP은 텍스트와 시각 표현의 코사인 유사도를 높이는 방향으로 학습하면서 동시에 symmetric cross entropy loss를 이용해 서로 다른 쌍의 유사도를 낮추는 방향으로 학습한다.
2. ESResNeXt
ResNeXt-50 을 기반으로 하였으며 훈련 가능한 시간-주파수 변환 기법을 이용한다. 30M개의 파라미터를 이용하여 학습하며 large-scale dataset인 AudioSet에서 competitive한 성능. 그리고 특정 데이터셋 UrbanSound8K, ESC-50에서 SOTA를 달성했다. 추가적으로 ESResNeXt는 multi-channel input의 implicit processing을 지원하면서, white Gaussian noise와 sample rate decrease 에 강건한 모델이다.
3. Hybrid Model - AudioCLIP
기존 Text, Image 를 갖는 CLIP을 더 발전시킨 모델로 Text, Image, 그리고 Audio-heads 세 개의 subnetwork를 갖는다. 기존의 CLIP이 text-to-image similarity loss를 갖는데, 본 모델에선 text-to-audio and image-to-audio similarity loss 를 추가했다 (3개의 modality를 가짐에 따른 이미지-오디오, 오디오-텍스트 조합이 새로 생겨나기 때문으로 보여진다). 세 조합 중 어떤 쌍을 이용하더라도 처리가 가능하다.
Experimental Setup
사용한 데이터셋, 데이터 증강 방법, 훈련 과정과 하이퍼파라미터, 성능 검증 방법을 설명한다.
1. Datasets
Composite CLIP Dataset
CLIP 저자에 의해 생성됨. 400M개의 text-image 쌍이고 이는 500k개의 text-based query에 기반함 (각 query는 약 20k의 pair를 포함). 이 연구에서는 간접적으로 CLIP 파트의 text, image heads 가중치 초기화에 이용됨- ImageNet
1000 종류의 1M 이상의 이미지셋. ESResNeXt의 가중치 초기화와 zero-shot 추론을 위한 target으로 이용됨 AudioSet
1.8M개의 데이터, 20k의 검증셋, 527 종류로 구성된 오디오 데이터셋. 각 데이터는 유튜브에서 가져온 최대 10초의 데이터로, 고유 ID와 시각 데이터로 구별된다.
이 연구에서는 AudioSet의 원본 유튜브 영상에서 영상 데이터 또한 추출해 이용하여 기본 (vanilla) CLIP network 와 tri-modal 확장 버전을 이어주었다. 오디오 부분과 label이 ESResNeXt 모델의 image-to-audio 전이학습에 사용되었으며, 해당 오디오 부분의 영상 클립이 hybrid AudioCLIP 모델의 input으로 사용되었다.
위를 더 자세히 설명하면, 영상 부분에서 동일한 간격으로 10개의 frame을 추출하고, 그중 한개를 무작위로 선정하여 AudioCLIP 학습에 이용한다. Evaluation에서는 앞과 달리 맨 중간의 frame을 고정적으로 이용한다.UrbanSound8K 8732개의 mono / binaural 오디오 트랙으로 구성. 16-48kHz 대역에서 추출됨. 최대 4초 이하. “에어컨”, “경적”, “노는 아이들”, “개 짖는 소리”, “드릴 소리”, “엔진 아이들링”, “총소리”, “공사 잭해머”, “사이렌”, “거리 음악” 10개의 분류로 이루어져 있다.
이 데이터셋을 이용해 AudioSet으로 훈련된 AudioCLIP의 zero-shot inference를 시행하였으며 audio encoding head를 fine-tune하는 데도 이용되었다.- ESC-50
단일채널 44.1kHz에서 추출된 5초 길이의 2000개 오디오 데이터셋. 이름에서처럼 50개의 클래스로 구별되며 동물, 자연, 물, 말하지 않는 사람, 내부, 외부 로 대분류로 나뉘어져 있다.
해당 데이터셋은 AudioCLIP의 zero-shot inference에 이용되었고 이 또한 audio encoding head fine-tune 에 이용되었다.
2. Data Augmentation
CLIP에 이용되는 데이터셋에 비해 오디오 데이터셋은 100배 적다. 따라서 데이터 증강 방법이 이용되었다.
Time Scaling
시간적으로 랜덤하게 늘이거나 줄임. time stretching and pitch shift를 같이 진행하여 이루어지는데 보통 계산 비용이 많이 소요되므로 여기에서는 [-1.5, 1.5] 구간에서 랜덤 선택하여 time-scaling을 설정함.Time Inversion
50%의 확률로 랜덤하게 뒤집음Random Crop and Padding
증강하지 않은 데이터셋의 가장 긴 트랙보다 짧거나 긴 데이터에서 임의의 부분을 padding하거나 crop하였다. evaluation에서는 임의 부분 대신 중간 부분만을 고정적으로 선택하여 padding 및 crop하였다.Random Noise
visual-related task에서 overfitting을 방지하기 위해 random noise 가 추가되곤 한다. 앞서 이야기했듯이 ESResNeXt model은 robustness evaluation을 통해 노이즈에 더 강건함을 보였다. 이에 따라 본 연구에서도 오디오에 화이트 가우시안 노이즈를 (AWGN) 10.0dB ~ 120dB 중 임의로 설정하여 25%의 확률로 노이즈를 추가하였다.
3. Training
Audio-head 에 Extended AudioSet pre-training을 진행했는데 이것이 ESResNeXt model의 성능을 향상시켰기 때문이다. 그 다음 나머지 두 head (text, image)와 함께 tri-modal로 훈련하였다.
종합적으로 AudioCLIP은 AudioSet 데이터셋에서 오디오 부분, 해당하는 비디오 프레임, 텍스트 라벨로 학습되었다. 그리고 audio-head는 UrbanSound8K와 ESC-50 데이터셋으로 audio-and-text 형식으로 fine-tuning되었다. Evaluation은 ImageNet 및 AudioSet, UrbanSound8K, ESC-50 을 이용하였다.
- Audio-Head Pre-Training
audio-head 파라미터 초기화는 두 단계로 이루어짐.ImageNet-initialized ESResNeXt가 Standalone 형태로 AudioSet을 이용해 train됨.
pre-trained 된 audio-head가 AudioCLIP에 통합되고 text and image head와 함께 재차 학습됨 통합 과정에서 pre-train 된 audio-head는 classification layer가 아웃풋 뉴런의 개수가 CLIP의 임베딩 공간 크기와 같은 형태로 랜덤하게 초기화됨.
이러한 셋업으로 audio-head의 output이 기본 CLIP model과 같은 형태로 나오게 되며, text-와 image-head는 audio-head의 2. cooperative pre-training단계에서 파라미터가 고정된다 (freeze). 그래서 두 head는 multi-modal 에서 선생처럼 작용할 수 있게 된다.
AudioCLIP Training
audio-head를 AudioSet으로 pre-train 했지만 이것의 이미지와 텍스트 분포는 CLIP dataset을 따르지 않으므로, 재차 전체 tri-modal 모델을 AudioSet을 이용해 학습한다. 그리하여 3개의 head 모두 함께 tune 되며 AudioCLIP 모델이 audio 샘플의 분포 뿐 아니라, image와 text의 분포 모두를 고려하게 한다.- Audio-head fine tuning
좀더 domain-specific하게 모델을 만들기 위해 UrbanSound8K, ESC-50 두 데이터셋으로 fine-tuning을 진행한다. 방법은 거의 pre-training 했던 것이랑 비슷함.
4. Hyper-Parameters
SGD with Nesterov’s momentum of 0.9, weight decay of 5*10^(-4) and batch size of 64
learning rate 지수적 감소하는 형태. $\eta$ 와 $\gamma$ 가 10^(-4) ~ 0.95 사이의 값을 가짐.
epoch은 AudioSet-based 훈련에서 30으로 설정, fine-tuning에서 50으로 설정
5. Performance Evaluation
Classification and Querying 두개의 task로 성능측정
Classification
AudioCLIP과 audio-head로 수행. audio-head의 아웃풋 수는 데이터셋 타겟 수와 같으므로 audio-head classification에서는 direct prediction이 이루어짐. AudioCLIP 에서는 text label에서부터 타겟을 빌딩하는 과정이 중간에 더해진다.Querying
Query 또한 이미지와 오디오에서부터 텍스트가 나오므로 Classification은 Querying의 하위 작업으로 여겨짐. ImageNet, AudioSet, UrbanSound8K, ESC-50 데이터셋에서 Querying 성능 측정. 점수는 Top-1 Precision/Recall (P@1, R@1), Mean Average Precision(mAP)로 측정
Results
1. Classification
Audio-head only
AudioSet 데이터셋을 이용한 30 epoch으로 늘어난 pre-train을 통해, MAP를 28->34%로 올림. 이는 downstream tasks에서도 성능 향상에 도움이 됨. UrbanSound8K, ESC-50에서 accuracy를 0.3%, 0.7% 향상. (이건 거의 성능향상이 없는 것 같긴한데..)AudioCLIP
기존 ESResNeXt 모델 대비, 비디오 프레임을 이용한 tri-model 셋업을 통해 audio-head’s target 분포에 다양상을 부여하고 오버피팅을 방지 및 오디오 분류 작업 성능을 향상시켰다.
Unseen한 데이터에서도 zero-shot 성능을 보였다.
2. Querying
CLIP에서 query를 부여하면 다른 모달리티에서 유사도 점수를 나타낸다. (텍스트 쿼리 -> 이미지 유사도)
텍스트 -> 이미지 : 같은 label set을 가진 이미지 샘플만이 관계있는 결과로 여겨짐.
ImageNet dataset에서는 Querying 성능이 낮아졌고, AudioSet 데이터셋와 분포가 다르기 때문으로 보여짐.
텍스트 -> 오디오 : 쿼리에 따라 오디오가 나오고 라벨이 쿼리와 매치되면 맞는 것으로 여겨짐. ESC-50의 경우 소폭 성능이 하강함.
이미지 <-> 오디오 : mAP로 측정. 쿼리 성능 모두 향상.
Conclusion
ESC 모델 구조를 결합하여 CLIP 모델을 오디오 모달리티에서도 이용 가능하게 발전
UrbanSound8K, ESC-50에서 SOTA 달성.
Zero-shot 추론에서 69%로 이전 시도 대비 높은 성능 달성 및 UrbanSound8K에서 새로운 baseline 설정 (68%)
Cross-modal querying 성능 측정 및 분류와 querying에서의 partial and full training 의 성능 차이도 측정
더 다양한 dataset과 task에 AudioCLIP 모델을 적용해 볼 예정. CLIP 대신 다른 형태의 backbone 설정을 통해 성능 향상을 더 이룰 수 있을 것이라 기대.